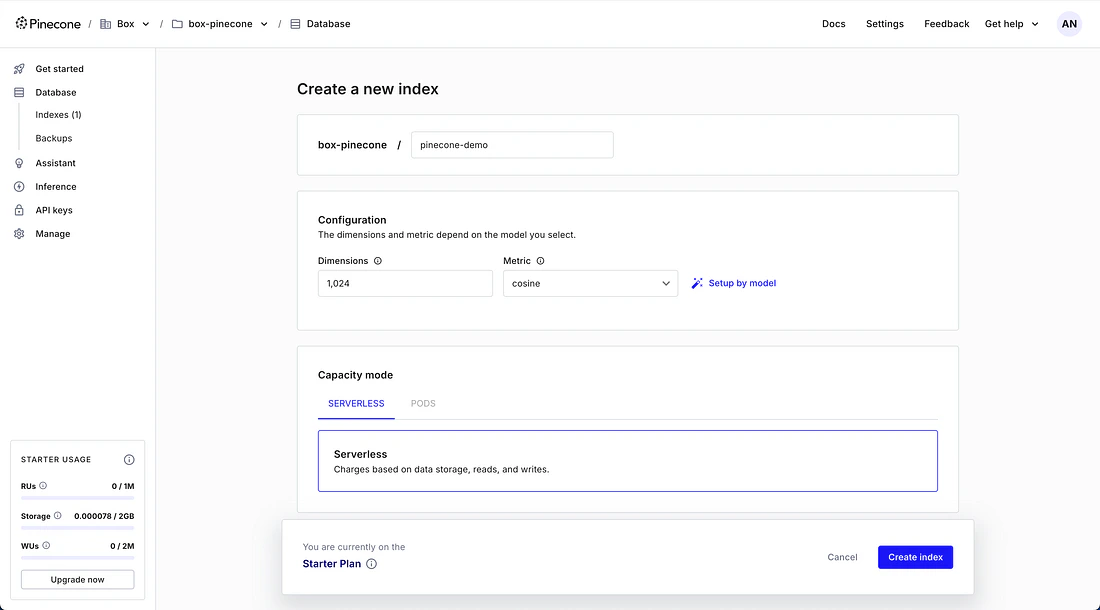
 Note the index name. You will add it to the configuration file.
Note the index name. You will add it to the configuration file.
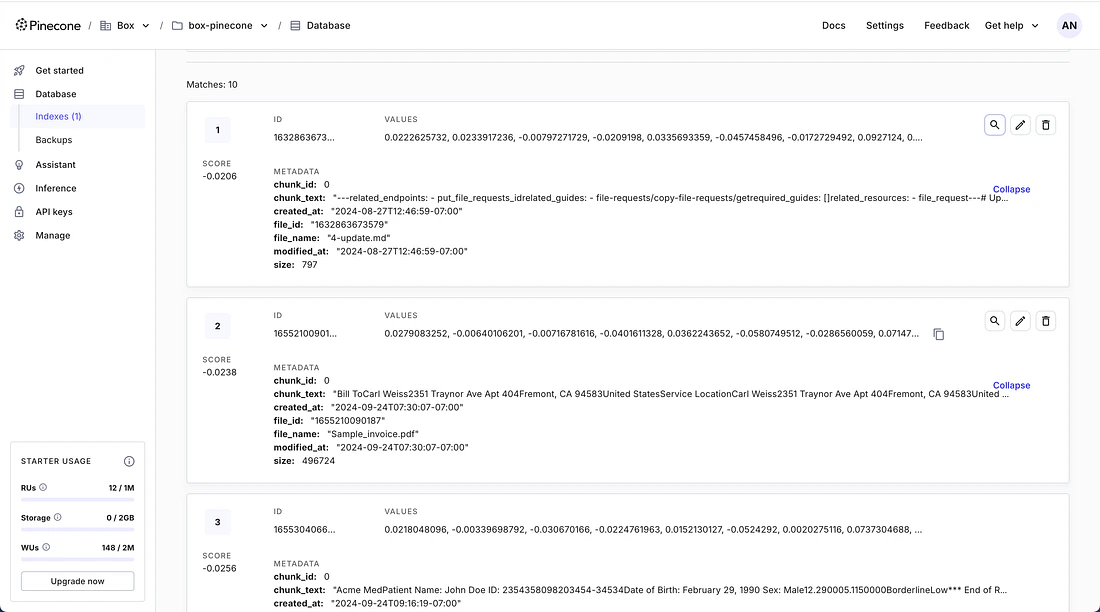 ## Query the LLM
With the embeddings stored, you can ask questions about your Box content.
This part of the project uses OpenAI as the LLM provider.
Run the query script:
```bash theme={null}
python query.py
```
Enter a question at the prompt. The script converts your question to an
embedding, retrieves the most relevant content chunks from Pinecone, and
sends them along with your question to OpenAI to generate an answer.
## Query the LLM
With the embeddings stored, you can ask questions about your Box content.
This part of the project uses OpenAI as the LLM provider.
Run the query script:
```bash theme={null}
python query.py
```
Enter a question at the prompt. The script converts your question to an
embedding, retrieves the most relevant content chunks from Pinecone, and
sends them along with your question to OpenAI to generate an answer.
 ## Enhancement ideas
## Enhancement ideas