fieldsパラメータを使用して構造を作成するか、すでに定義済みのメタデータテンプレートを使用できます。テンプレートの作成の詳細については、メタデータテンプレートのカスタマイズを参照するか、を使用してください。また、抽出エージェント (標準または強化) を使用して、テンプレートにメタデータを自動入力することもできます。
サポートされているファイル形式
このエンドポイントでは、以下のファイル形式がサポートされています。ドキュメント
ドキュメント
- DOC
- DOCX
- GDOC
- ODT
- Box Note
- テキスト
- RTF
- XDW
- AS
画像
画像
- TIFF
- TIF
- PNG
- JPEG
- JPG
- WEBP
スプレッドシート
スプレッドシート
- PPT
- PPTX
- GSLIDE
- GSLIDES
- ODP
- OTP
- XLS
- XLSX
- XLSM
- ODS
- CSV
コードファイル
コードファイル
- 言語:
.js、.py、.css、.php、.sql - JSON
- HTML
- XML
- MD
サポートされている言語
Box AIは、以下の言語のドキュメントからメタデータを抽出できます。- 英語
- 日本語
- 中国語
- 韓国語
- キリル文字ベースの言語 (ロシア語、ウクライナ語、ブルガリア語、セルビア語など)
開始する前に
Platformアプリを作成して認証するには、に記載されている手順に従っていることを確認してください。リクエストの送信
リクエストを送信するには、POST /2.0/ai/extract_structuredエンドポイントを使用します。
パラメータ
コールを実行するには、以下のパラメータを渡す必要があります。必須のパラメータは太字で示されています。items配列には要素が1つだけ含まれている必要があります。プロンプトとファイルの制限については、を参照してください。
structおよびtableフィールドタイプ
Box AI extract_structured APIでは、既存のスカラータイプ (string、float、date、enum、multiSelect) に加え、2つの複雑なフィールドタイプ (structおよびtable) がサポートされています。structおよびtableタイプを使用すると、ドキュメントからグループ化された構造化データや繰り返し構造を持つ構造化データを抽出することができます。
structフィールドタイプ
structタイプを使用すると、関連する複数のサブフィールドを1つの名前付きJSONオブジェクトにグループ化することができます。これは、関連するひとまとまりの値を抽出し、個別のフラットなフィールドではなく、1つの構造化されたオブジェクトとして取得する必要がある場合に便利です。例としては、住所や個人の連絡先情報などを挙げることができます。
structフィールドには、そのサブフィールドを定義するfields配列が必要です。各サブフィールドは、以下のプロパティを持つオブジェクトです。
key: サブフィールドの一意の識別子。type: サブフィールドのタイプ。サポートされるタイプは、string、text、number、float、boolean、date、enum、multiSelect、およびarray[<simple_type>]です (例:array[string])。ネストされたstructまたはtableタイプは、サブフィールドとしてサポートされていません。displayName: サブフィールドの表示名。description: サブフィールドの説明。prompt: サブフィールドに関する追加のコンテキスト。サブフィールドの確認方法やフォーマットの方法を含めることができます。
structフィールドタイプに対するリクエストの例
tableフィールドタイプ
tableタイプを使用すると、構造化データの繰り返し行をJSONオブジェクトの配列として抽出できます。この場合、各オブジェクトが1行を表します。
これは、ドキュメント内に同じデータ構造のインスタンスが複数含まれている場合に役立ちます。例としては、請求書の明細項目や税率表の項目などが挙げられます。
tableフィールドには、各行の列 (サブフィールド) を定義するfields配列が必要です。サブフィールドのプロパティおよびサポートされるタイプは、structのものと同じです。
出力はJSONオブジェクトの配列であり、各オブジェクトは抽出された1行を表します。
tableフィールドタイプに対するリクエストの例
サポートされるサブフィールドのタイプ
構造および表のフィールド内で、以下のタイプがサポートされています。チュートリアル: サプライヤ契約書を構造化された調達データに変換する
structとtableの2つのフィールドタイプの実際の使用例を見ていきます。サプライヤ契約書から、グループ化されたベンダー詳細データと繰り返しの納品スケジュールを抽出したうえで、結果を下流の調達レコードにマッピングする方法を確認できます。ユースケース
この例では、サンプル請求書から構造化された形でメタデータを抽出する方法を示します。ベンダー名、請求書番号などの詳細情報を抽出する必要があるとします。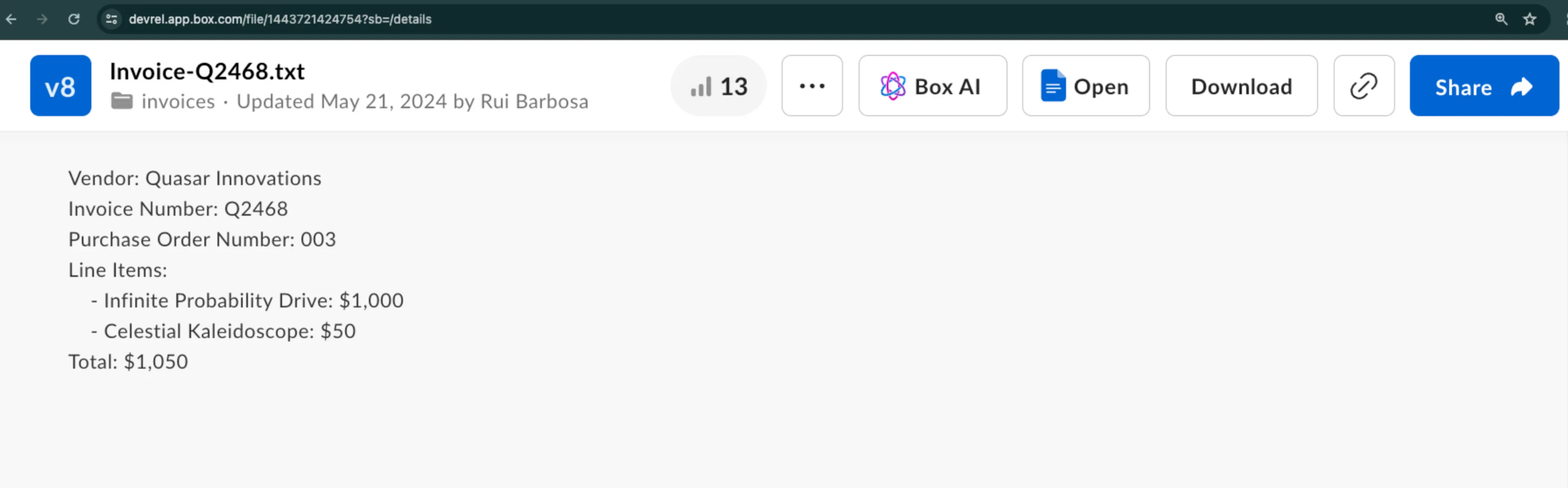
リクエストの作成
Box AIから応答を取得するには、以下のパラメータを使用して、POST /2.0/ai/extract_structuredエンドポイントを呼び出します。
items.typeおよびitems.id: データの抽出元となるファイルを指定します。fields: 指定したファイルから抽出するデータを指定します。metadata_template: 既存のメタデータテンプレートを指定します。
fieldsとmetadata_templateのどちらかを使用して、構造を指定できます。両方を使用することはできません。fieldsパラメータの使用
fieldsパラメータを使用すると、抽出するデータを指定できます。各fieldsオブジェクトにはパラメータのサブセットがあり、それを使用して、検索対象のデータに関する情報を追加できます。たとえば、フィールドのタイプや説明、さらには追加のコンテキストを含めたプロンプトを追加することができます。
メタデータテンプレートの使用
メタデータテンプレートを使用する場合は、そのtemplate_key、type、scopeを指定します。
抽出エージェント (強化)
抽出エージェント (強化) を使用するには、次のようにai_agentオブジェクトを指定します。
- インラインでのフィールド定義 (フィールドが頻繁に変わる場合に最適)
- メタデータテンプレート (フィールドが一定である場合に最適)
チュートリアル: Box AI Extractを使用した請求書取り込みの自動化
抽出 (構造化) の実際の動作をご確認ください。フォルダの監視、請求書のフィールド抽出、各ファイルへのメタデータ書き戻しを実行する、エンドツーエンドの自動化を構築します。